AI Content Licensing Must Pay for the Machinery of Truth

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Authored On
Modified
AI answers are weakening the traffic bargain that once supported original reporting Licensing can compensate publishers, but it cannot guarantee reliable AI outputs A fair settlement requires transparency, attribution, collective bargaining and funded verification

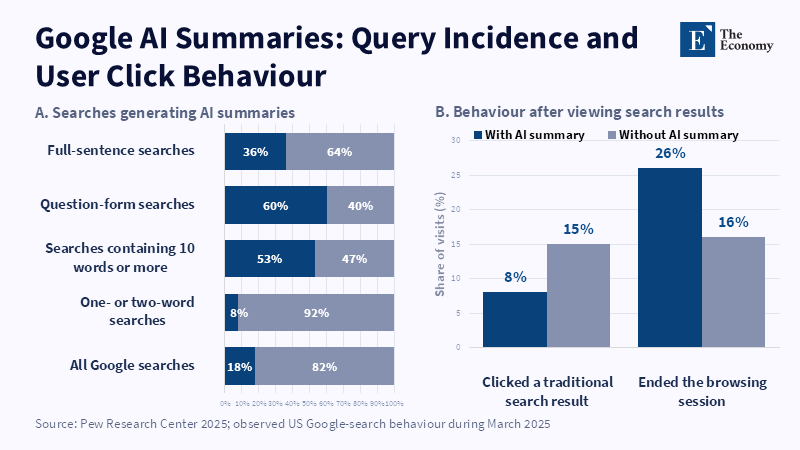
When Google displayed an AI summary of a query, users clicked through to a standard result only 8% of the time. Without the summary, it was 15%. Only 1% of users clicked through to a source link embedded in the AI answer. Those statistics reveal the new bargain of the web. Users still ask questions. Publishers still support reporting, editing, legal checking, correcting and expert validation. But the platform can now answer the question before the reader gets to the source. AI content licensing is often framed as a copyright debate about repurposing text. That framing is too narrow. The core problem goes beyond pricing words. It is about who underwrites the expensive labor that makes current knowledge valuable. A truly fair licensing settlement must do more than put a value on words. It must underwrite the verification process, preserve access to original sources and prevent a handful of platforms from setting both the toll and the rules governing payment.
AI Content Licensing Must Replace the Broken Traffic Bargain
The previous search model was never benevolent, but it contained an exchange. Publishers allowed their articles to be crawled. Search engines returned their pages to readers. Those readers could turn into subscriptions, advertising revenue, donor funding, sales, or brand loyalty. Generative search undermines that marketplace. It harvests facts, context and syntax from a multitude of sources and constructs a single finished answer. The consumer has nothing compelling to return to. This is not the end of the search. This is a shift in circulation. Knowledge still flows, but it flows through a synthetic answer instead of a link to the organization that created it. AI content licensing matters because this new form of circulation separates use from payment. The answer engine receives a valuable commodity. The publisher retains the expense of producing the original source. So long as that divide persists, trustworthy information becomes an unpaid input to systems that can curtail the demand for their originating work.
This shift is visible before AI chatbots become the dominant source of news. In 2026, only around 10% of people across 48 markets reported using chatbots for news. But publishers were already experiencing a steep decline in search traffic. Worldwide organic Google search traffic to over 2,500 news outlets declined by roughly a third from late 2024 to late 2025. Media owners predicted search referrals would drop by a further 43% over three years. What makes these figures significant is that they are already visible. A platform does not require the complete domination of news outlets to hamper their business model; it merely needs to capture the highest-value queries and limit the number of users leaving for other interfaces. Correspondingly, the shrinkage first manifests itself in referrals, direct relationships and subscription viability. Therefore, AI content licensing is not a response to a distant possibility, but to an ongoing revenue shift.
Some argue that publishers benefit by having their work reflected in an answer. That may be true for products, travel arrangements, or software companies that profit after you identify their brand. It is much less true for journalism and public interest research. A local investigation that was costly to produce cannot recoup expenses when a chatbot uses its findings to answer a query. A courtroom report cannot gain a new subscriber by contributing its facts to a summary. And a source label has little value when most users never view it. Attribution does matter. But it is not payment, audience control, or proof of fair use. The new policy question is not whether AI can and should use publicly available information. It is whether companies that produce commercial answers based on expensive reporting should support the institutions that produce, fact-check and defend that reporting.
The Real Product Is Verification, Not Text
Most licensing deals are based on licensing access to the content. The more valuable assets are the processes that created it. Calls, records, source checks, editing, legal review, industry expertise, correction and then the time to turn the product around-these are the slow, expensive elements of production. That work becomes less visible once the reporting is compressed into a short paragraph. An AI system can copy that final paragraph without absorbing the cost of the process. It can also inherit the source’s credibility. It can obscure the labor behind the source. This is why licensing content shouldn't be approached as a bulk buy on words. It is more like a subscription to an active payment for access to an active verification system. The premium in licensing is in the provenance, timeliness and accountability that allow a reader to identify and understand their source for themselves. A marketplace that only pays on volume production will favor scale. A marketplace that values verification and accountability will pay for quality.
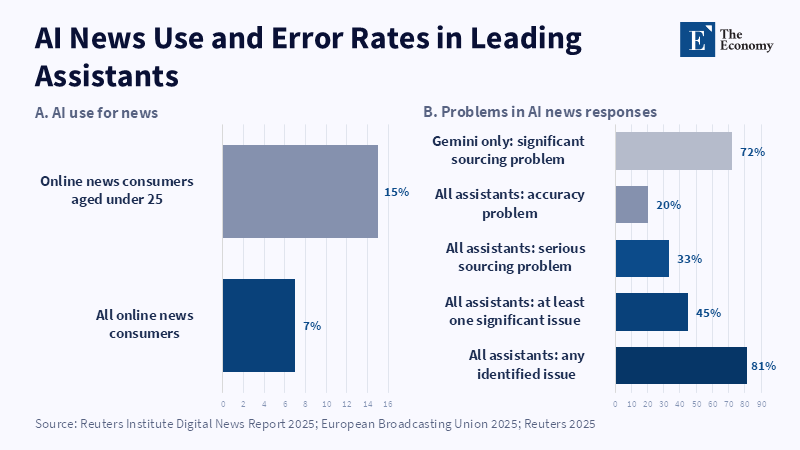
Licensing alone cannot make an AI produce a factual answer. A pre-trained model applied to material from high-quality sources can still hallucinate a date, conflate two events, confuse a name, or assert an unsupported fact confidently. Experiments on semantic entropy indicate that errors in the model are not eliminated by better documents alone. A large international study of leading AI assistants reported 45% of supplied trials had at least one significant issue; 31% had sourcing problems and 20% contained inaccurate information. These failures are important, as the source is not merely used like a search engine. It is understood, amalgamated and rewritten. AI licensing can enhance access to current material, but it cannot supersede uncertainty controls, transparency of sourcing, or a requirement to abstain if evidence is weak. A paid source can be quoted badly. An archived one can support a false conclusion. Remuneration and model reliability must therefore be governed together.
There are concrete implications for editors, teachers, archivists, librarians, research managers and public institutions. An institution should not accept a clean AI answer as a substitute for the record. It needs standards to maintain the claim-to–source trail. High-stakes applications must have visible citations, direct access to the original and human validation. AI systems should be required to flag whether material is quoted, summarized, inferred, or generated from uncertain sources. Administrators commissioning AI should have guarantees for tracking usage, constraining sourcing and making corrections. Teachers should make source checking part of standard research training. Policymakers must support shared verification services where markets fail, starting with local news, minority-language reporting and public-interest research. The goal is not to inhibit AI developers. It is to ensure that convenience does not erase the chain of responsibility behind a claim.
A Fair AI Content Licensing Market Needs Public Rules
Private arrangements have demonstrated a willingness on the part of some AI companies to pay for quality, but have not demonstrated that the market will operate fairly. Big publishers are able to employ lawyers, track usage and negotiate with the largest platforms. Smaller outlets rarely can. Bilateral bargaining thus poses an obvious danger. The most prominent brands will secure licensing fees, while local, trade, ethnic and minority language sources will be left unpaid or invisible. The same platforms that diminish referrals then threaten to allocate which publishers will gain replacement income. This is not truly a competitive market in the traditional model. It presents a new dependence. Licenses for AI content use require common standards because the market is forming without equal bargaining power or equal access to information. Publishers often lack visibility into where, how often and in what context their work was used. Without usage data, it is difficult to set fair prices. Without collective effort, weaker publishers are bound to be left with unfavorable deals.
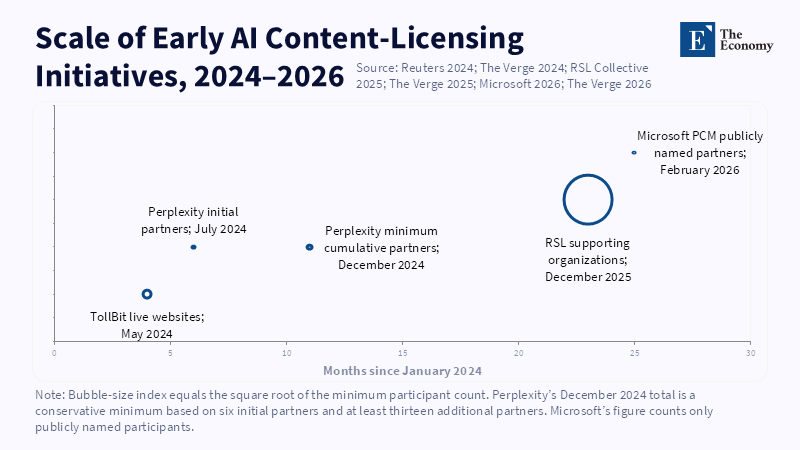
A stronger model would bring together the legal, the collective and the technical. The legal layer should impose a duty to pay when copyrighted works are used for specific commercial purposes. Collective organizations could broker and apportion the fees across many rights holders. And machine-readable rights management tools might specify whether text and images could be used for training, retrieval, analysis, or generation. Standardized reporting would delineate crawl volumes, source appearances, referrals and royalty streams associated with AI response outputs. Provenance standards would track origin and iterations of material. Competition authorities must then prevent platforms from simultaneously functioning as purchaser, marketplace administrator, measurement provider and rule-maker. The aim is not to set a price for every URL. A fair market would allow rights holders to bargain with firms that profit from their work, where rights allocation, attribution and remuneration are transparent and no single transnational platform abuses its collective market power.
The usual argument is that a formal licensing requirement will increase costs, block the entry of new data and slow down progress in AI. (The worst kind of scheme could achieve all three.) But the existing voluntary regime does precisely that. It already excludes newcomers, imposes costly negotiations on every user and strips many creative firms of a route to profits. A well-designed statutory regime can address these issues. For the European Parliament, economic research suggests that compulsory licensing can beat the weaker alternatives under a wide set of realistic assumptions, in particular where the goal is preserving the future flow of a high-quality data resource. Innovation depends upon that resource. Systems that seek to make the best use of trustworthy data while freezing out its producers are not sustainable. They are benefiting from a resource they cannot replace. The test is not whether licensing is cheaper for AI today, but whether it keeps available the credible, current and diverse information that will be needed for future models.
From Private Deals to a Verification Settlement
A resilient settlement requires four linked obligations. AI firms should pay for bounded uses of safeguarded content. They should reveal enough detail of training and retrieval to enforce those rights. Their outputs should provide clear attribution and public access to original sources. They should also capture new claims generated in synthesis. This last requirement is significant because a model is not a neutral conduit. It selects, compresses and blends by design. Where evidence is uncertain, the model should communicate doubt instead of persisting with a single confident output. Where a source updates or corrects a claim, the synthetic output should be refreshed accordingly. Public funding should enable verification work that has high societal importance but limited profitability. Local reporting, archives, fact-tracking networks and underserved language communities fit this category. AI content licensing must support this shared infrastructure rather than the private market of a few multinational outlets.
That 8% clicking rate should be thought of as much more than a traffic statistic. It is an early indicator of the answer layer's ability to assume responsibility for the user relationship, with the source absorbing the cost of truth. A highly consolidated licensing market may delay that loss in the hands of a handful of large publishers, but it will not save the wider information ecosystem. The settlement needed is far greater. Payment must follow use. Attribution must go beyond the answer and trace back to the source. Rights are meaningless without enforceability across markets. Small publishers must be able to bargain collectively. Models must disclose uncertainty and correct errors. Verification must be funded as a public good as well as a private transaction. AI content licensing will succeed when it serves the institutions on which AI answers are built. There is no choice between protection and progress, only between an AI economy that sustains its information base and one that depletes it.
This article is based on an original research article published by The Economy Research. For the original version, please refer to From Search Traffic to Synthetic Circulation: AI Content Licensing and the Political Economy of Verification.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
Chapekis, A. and Lieb, A. (2025) ‘Google users are less likely to click on links when an AI summary appears in the results’, Pew Research Center, 22 July.
Deck, A. (2026) ‘The emerging AI content licensing market puts news publishers in a “double bind,” a new report warns’, Nieman Journalism Lab, 27 May.
Egan, J., Fletcher, R., Robertson, C.T., Ross Arguedas, A., Nielsen, R.K. and Newman, N. (2026) Digital News Report 2026. Oxford: Reuters Institute for the Study of Journalism.
European Broadcasting Union (2025) News Integrity in AI Assistants: An International Public-Service Media Study. Geneva: European Broadcasting Union.
Farquhar, S., Kossen, J., Kuhn, L. and Gal, Y. (2024) ‘Detecting hallucinations in large language models using semantic entropy’, Nature, 630, pp. 625–630.
Google Search Central (2026) ‘Google’s guide to optimizing for generative AI features on Google Search’. Google.
Kelly, R. (2026) ‘AI content licensing deals: June 2026 update’, Media & the Machine, 3 June.
Microsoft Advertising (2026) ‘Publisher Content Marketplace’. Microsoft.
Newman, N. (2026) Journalism, Media, and Technology Trends and Predictions 2026. Oxford: Reuters Institute for the Study of Journalism.
Newman, N., Ross Arguedas, A., Robertson, C.T., Nielsen, R.K. and Fletcher, R. (2025) Digital News Report 2025. Oxford: Reuters Institute for the Study of Journalism.
Peukert, C. (2025) The Economics of Copyright and AI: Empirical Evidence and Optimal Policy. Brussels: European Parliament.
Radsch, C.C. (2026) ‘Same gatekeepers, new tollbooths in the AI content licensing market’, Brookings Institution, 9 June.
Radsch, C.C. and Montoya, K. (2026) Same Gatekeepers, New Tollbooths: Mapping the AI Content Licensing Market. Washington, DC: Open Markets Institute.
Reuters (2024) ‘Multiple AI companies bypassing web standard to scrape publisher sites, licensing firm says’, 21 June.
Reuters (2025) ‘AI assistants make widespread errors about the news, new research shows’, 21 October.
Robison, K. (2024) ‘Perplexity is cutting checks to publishers following plagiarism accusations’, The Verge, 30 July.
Roth, E. (2025a) ‘A pay-to-scrape AI licensing standard is now official’, The Verge, 10 December.
Roth, E. (2025b) ‘The web has a new system for making AI companies pay up’, The Verge, 10 September.
Roth, E. (2026) ‘Microsoft says it is building an app store for AI content licensing’, The Verge, 3 February.
Sadeghi, M., Dimitriadis, D., Padovese, V., Pozzi, G., Badilini, S., Vercellone, C., Huet, N., Fishman, Z., Pfaller, L. and Adams, N. (2026) ‘Tracking AI-enabled misinformation: AI content farm sites and false claims generated by artificial intelligence tools’, NewsGuard.
The Economy Editorial Board (2026) ‘Trusted information is the new mainstream’, The Economy, 16 June.
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.